
First, let's make something clear... A case can easily be made for either TensorFlow or PyTorch, depending on your situation. The internet is full of articles pitting each of these AI frameworks against each other, but there are far fewer articles about companies explaining why they chose one over the other.
Except maybe a recent blogpost by Facebook explaining their choice - PyTorch builds the future of AI and machine learning at Facebook. It’s an interesting article that has a few surprising takeaways about why the creators of PyTorch are embracing their own technology.
This is why at Deeplite, we thought it would be interesting to share our own reasons for selecting PyTorch.
First, a quick background on us. Deeplite was founded in 2019 to help close the gap between the high computational requirements of deep neural networks and the computational capabilities that surround us, or as our tag line mentions "AI for everyday life". Not every edge device can be running on GPUs, which is why we’re looking to help deep learning engineers run their models smaller, faster and more energy efficient.
Ease of Use
PyTorch has a C++ interface, which provides a lot of advantages for deployment, but it's mostly pythonic. Python is not the only code out there, but it is one of the most popular languages used by data scientists. This helps us in a number of ways, one of them being for recruiting, since so many deep learning engineers are already trained on Python.
PyTorch's active community of developers are engaged and constantly working towards improving usability. It also has a very well organized documentation. On top of these, the number of public repositories of PyTorch based models is growing at a much faster rate than repos for TensorFlow models.
Since 2018, PyTorch natively supports ONNX, so you can export models in the standard Open Neural Network Exchange format. By having an ONNX model output, it allows developers to easily move their models between different tools - this flexibility provides easier access to compatible platforms and run-times. Previously, this lack of flexibility to deploy models across different platforms was a significant gap that PyTorch had vs. TensorFlow.
Around the office there’s a shared opinion that TensorFlow’s ever changing API structure makes running TensorFlow models across different versions very difficult. For example, TF1 with Keras, TF1 without Keras, TensorFlow-slim and TF2 are mostly not compatible with each other. Another challenge with TensorFlow is that its versions are tightly coupled with CUDA versions – the ensuing version incompatibility makes it very difficult to run TF models across different platforms.
PyTorch uses a dynamic graph – which enables easy debugging. While the last 4 releases of TensorFlow included the use of a dynamic graph, the graph has a “thread lock” which makes it difficult to impute. In our experience, we find that being able to define or manipulate your graphs on-the-go comes in handy. Modifying inputs during runtime offers our programmers access to the inner workings of the network and greatly simplifies debugging.
Finally, PyTorch is easy to install and it’s compatible with different CUDA version. The backwards compatibility is great and helps our team with productivity.
PyTorch is Preferred by Academics
PyTorch is better suited for those that have a deeper understanding of deep learning concepts. Hence, it is preferred by academics, who are at the forefront of the latest innovations of deep learning models.
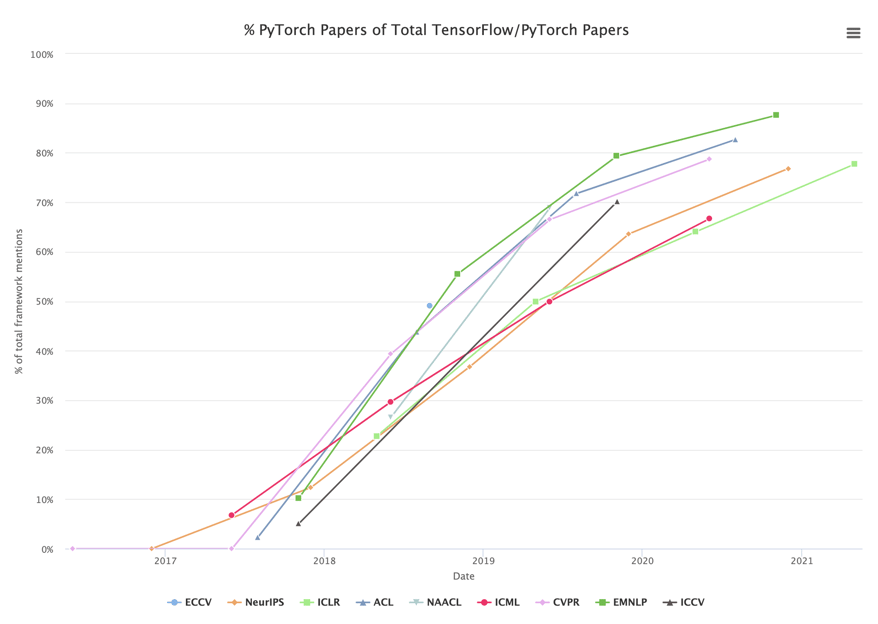 There are various sources of information out there that show PyTorch’s growing popularity - here’s an interesting research done by Horace Me published on the State of Machine Learning Frameworks that shows that the use of PyTorch among academics is increasing.
There are various sources of information out there that show PyTorch’s growing popularity - here’s an interesting research done by Horace Me published on the State of Machine Learning Frameworks that shows that the use of PyTorch among academics is increasing.
This is very important to us, because while academia is helping move certain fields forward, like computer vision, our industry partners are constantly looking to bring these latest advances in deep learning to the real world. This is the area we’re focused on – helping our customers run the latest and greatest models in a cost-effective way (I.e. using fewer computing resources).
This is why we currently use PyTorch for our AI development.