
Two tremendous innovation movements are happening in the edge device industry today that we at Deeplite find particularly fascinating. What are they? That is, of course, the rise of deep learning and the RISC-V computer architecture progress!
Deep neural nets (DNNs) have become the de facto solution for many applications, such as audio “wake word” detection (i.e., “Hey Alexa” to wake-up a device) and, more recently, “visual wake words” detection (i.e., detect a person via a camera to wake-up). The versatility and ability of DNNs to scale performance as available data grows have led to breakthroughs in complex and high-value predictions.

On the hardware side, RISC-V is an instruction set for modular, low-cost computer architectures. If you’re not familiar, RISC-V is a shift from architectures that are proprietary, highly complex and expensive (e.g., bazillions of dollars to license IP for RISC from ARM) to a more open, modular approach to designing and licensing computer architectures. The RISC-V movement has been pioneered by a handful of innovators like David Patterson, SiFive, and our good friends at Andes Technology, a founding platinum member of the RISC-V foundation.
So where are we going with this? At Deeplite, we love innovation, but more than that, we love to combine cutting-edge tech with passion and experience to create AI for everyday life. Thus, we decided to experiment and combine the best optimized deep learning models and low-power RISC-V CPU cores to make more intelligent and efficient edge devices.
We worked with Andes Technology (one of the RISC-V movement innovators mentioned above) using our Deeplite Neutrino software to create faster, smaller, and more accurate deep learning on the AndeStar V5 RISC-V CPU cores, the first commercially available RISC-V CPU with DSP and vector extensions. The main idea here was to show complex AI person detection running on a very small, very affordable processor that could fit in a battery-powered edge device.

Let’s dig in to see how it all works!
As mentioned before, our goal was to detect people using an optimized AI model on Andes hardware.
The first step was to choose the model, dataset, and constraints. The model was MobileNet-v1.0, trained on the Visual Wake Words (VWW) dataset, a person subset of the COCO dataset. The constraints are related to the target device. As we ideally want to use a battery-powered camera that will need to run multiple other features and functions, we went with the least resource-demanding processor, an AndeStar V5 RISC-V CPU with <256KB of on-chip SRAM. This chip can run inference computation for the MobileNet model using the TensorFlow Lite Micro framework in INT8 precision.
Lastly, we set the accuracy constraint at >80%, or roughly a little bit higher than an implementation from the tinyML textbook in TensorFlow Lite Micro.
Now that we have our constraints and dataset, we needed a trained model to optimize. Since we had only 256KB of memory available, we wanted to use a model that is both compact, but also as accurate as possible. We trained the MobileNetv1-0.25x Floating Point, 32 model, on the VWW dataset in the PyTorch framework, a very popular, highly functional AI framework to surpass our acceptable accuracy limit. This was done to serve as our starting point for model optimization.
We also needed a model to serve as our reference point for the size, accuracy and latency. As the RISC-V CPU supported TensorFlow, we used the MobileNetv1-0.25x INT8 reference model was MobileNet-v1-0.25x INT8 in TFLite Micro (from tinyML textbook).
You can see the specs for these models in the table below.
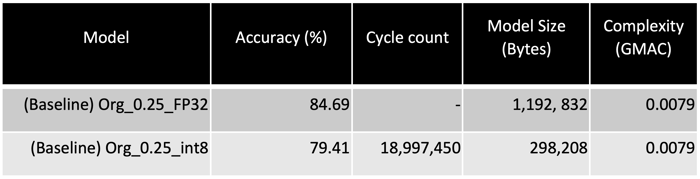
Now that we trained our PyTorch model to achieve acceptable accuracy, we need a model that is both accurate and optimized to maximize performance on the target hardware.
Traditionally, one might say: “we already have the quantized model and low overhead inference engine in TensorFlow Lite Micro, isn’t that enough?” Yes, such a model can run on a device. However, there are two very significant tradeoffs with this approach. First, we lose a significant amount of accuracy by using the smaller reference model. Second, we are leaving additional latency, size and power savings on the table by not optimizing our models! Off-the-shelf models like MobileNet, ResNets, or even Efficient/ShuffleNets can be optimized based on a user’s target application, acceptable accuracy, available hardware and resource constraints – parameters that must be considered for a successful real-world DNN deployment. Thus, we investigated the benefits of model optimization to save battery life on the target hardware while preserving accuracy. This is where our DNN model optimization software, Deeplite Neutrino, comes in.
By only passing the trained PyTorch model, dataset and target accuracy to the software engine, we automatically produced AI models that were smaller, more efficient and more accurate than our TensorFlow Lite Micro reference. This is made possible by Deeplite’s automated design space exploration technology and a handful of user-guided controls, such as quantizing the number of convolution filters per layer to the power of 4. The optimization happened on-premise using 1 GPU, without sending any data or models to the cloud. What used to take weeks or months was completed in days thanks to automated model optimization!
You can see the improvements in size, complexity and accuracy after model optimization in the table below.

You may think: “We have the model; it’s small, it’s accurate, so what’s left?” It turns out there’s one more step before we can use our optimized model in the real-world.
Remember how we started in PyTorch to boost our model accuracy? Well, the PyTorch inference engine and overhead just isn’t compatible with our edge device! Fortunately, the Andes team could easily convert their optimized model thanks to Neutrino’s ONNX exportability. The team simply converted the model to tf.keras and used TFLite Micro quantization and an inference engine to produce an optimized INT8 model ready for their hardware.
The last step is to run our optimized model on the device to measure the real-world performance and benefits of model optimization. The Andes team used the optimized MobileNetv1-0.25x INT8 models produced by Deeplite to see how much power we save per inference by leveraging model optimization. You can see the results in the figure below, where we demonstrate a 15% reduction in inference latency on the RISC-V CPU core (measured by cycle count per inference) and a 2% accuracy increase compared to the TFLite Micro reference model.
What does it mean? Deeplite optimized models are faster, smaller and more accurate!
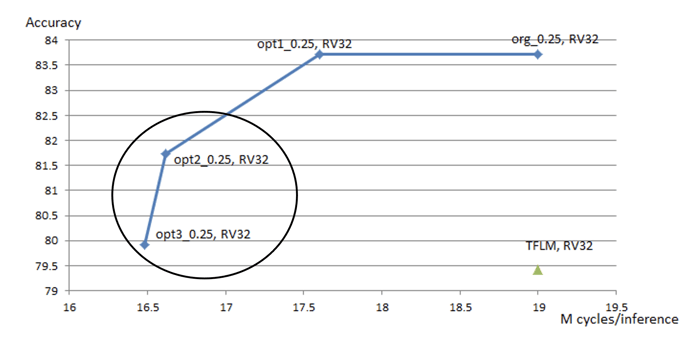
So that’s how we could combine the best of optimized deep learning models and RISC-V CPU cores and empowered Andes to implement faster, smaller and more accurate ‘person detection’ on ultra-low-power & low-cost AI edge hardware. Want to learn more about the application? Follow the link to download the full case study.

Curious to embed person detection abilities in your AI-enabled camera, drone, or vehicle? Contact us, and we will be happy to share a demo!