
Words can have multiple meanings. As a result, people involved with adjacent areas of the technology industry often misunderstand each other, even when using the same terms. Each group has its own frame of reference, history and technical domain expertise.
In particular, areas of technology cross-overs and convergence are often fraught with category errors, flawed assumptions – or just poor communications. There is a significant risk that this is occurring in the area of Edge AI. At least four different groups interpret that term in very distinct ways.
For example, many professionals in the cloud and network world have no idea about what can be achieved with optimized Edge AI on devices, either currently or what is likely soon – and what that implies for their own visions of the future. The telecoms industry, in particular, appears to be at risk of missing an important "disruption from adjacency".
This article is aimed at helping these people talk to each other, better understand each others' needs and expectations – and also help them avoid poor decisions through a lack of awareness of broader tech trends.
If you asked representatives of the following industries to play "word association" with the phrase "Edge AI", they might suggest very different explanations:
Someone involved in image detection or speech analysis might mention the trends towards "model compression" or "AI optimization", with heavy, resource-consuming or slow cloud-based inferencing shrunk down to work more efficiently on a CPU or microcontroller on a device – for instance a camera or smartphone. This is "AI at the edge" for them. It may solve multiple problems, from lower latency to reduced energy consumption (and better economics) for AI.
Someone involved with building a connected vehicle, or the quality-control for a smart factory, might think about a local compute platform capable of combining feeds from multiple cameras and other sensors, perhaps linked to autonomous driving or closed-loop automation control. Their "edge AI" resides on an onboard server, or perhaps an IoT gateway unit of some sort.
A telecom service provider building a 5G network may think of Edge AI both for internal use (to run the radio gear more efficiently, for instance) and as an external customer-facing platform exploiting low-latency connections. The "mobile edge" might be targeted at a connected road junction, video-rendering for an AR game, or a smart city's security camera grid. Here, "Edge AI" is entwined with the network itself – its core functions, "network slicing" capabilities, and maybe physically located at a cell-site or aggregation office. It is seen as a service rather than an in-built capability of the system.
For companies hosting large-scale compute facilities, AI is seen as a huge source of current and future cloud demand. However, the infrastructure providers often won't grasp the differences between training and inferencing, or indeed the finer details of their customers' application and compute needs. "Edge" may just mean a datacentre site in a tier-3 city, or perhaps a "mini datacentre" serving users in a 10-100km radius.
These separate visions and definitions of "Edge AI" may span as much as 10 orders of magnitude in terms of scale and power – from milliwatts to megawatts. So, unsurprisingly, the conversations would be very different – and each group would probably fail to recognize each other's "edge" as relevant to their goals.
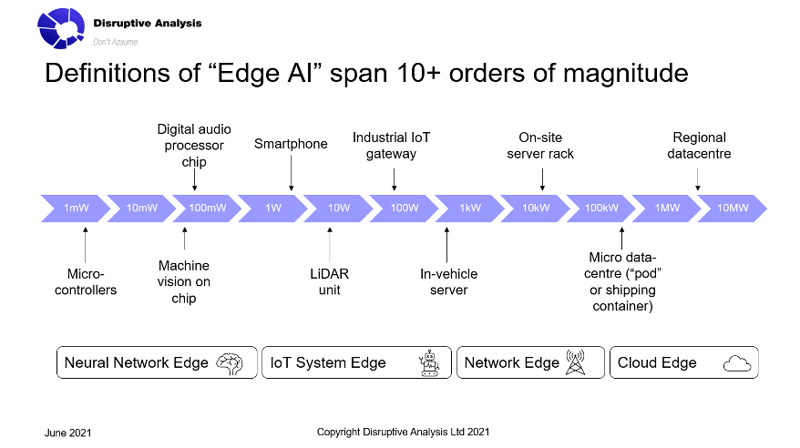
These are not the only categories. Others include chip and module vendors, server suppliers, automation and integration specialists, cloud/edge platforms and federation enablers and so forth. Added to these are a broad array of additional "edge stakeholders" – from investors to government policymakers.
Why does this matter? Because AI applications ultimately fit into broader ecosystems, transformation projects, consumer and business products or even government policy and regulatory regimes. In most cases, all of these groups will need to organize themselves into a value chain, or at least depend on each other.
Often, edge-AI market participants focus – understandably – on what they perceive as their unique capabilities, whether that is their preferred models, their physical premises, network/system speeds and their existing customer relationships. And internally, they are looking for new revenue opportunities and use-cases to help justify their investments, as well as gain more "customer ownership".
But the questions which don't get asked often enough are "What does the developer – and the final end-user – really value? What are their constraints? And how will that drive their decision choices, now or in the future?"
For instance, consider an application developer working on an AI-powered object recognition tool. At the moment, their product has a few problems to resolve. In particular, the response times are laggy, which reduces the effectiveness and market opportunity of the overall solution. Given the round-trip time of video images to and from the cloud, plus the significant processing load and inference time, they can only get one reliable response per second, and the implied cost means it's only suitable for certain high-value tasks.
That's fine for monitoring crowds and lost property in a railway station – or detecting a particular parasitic beetle on a crop-leaf – but isn't useful for spotting defects on a fast production-line conveyor or to react to a deer jumping in front of an autonomous vehicle.
For the next version of their product, they have a range of different improvement and optimization paths they could pursue:
However, latency is not the only criterion to optimize for. In this example scenario, the developer's cloud-compute costs are escalating and they are facing ever more questions from investors and customers about issues of privacy and CO2 footprint. These bring additional trade-offs to the decision process.
Indeed, at a high level, there are numerous technical and practical constraints involved, such as:
Looking through this list – and also considering all the other AI-related tasks, from audio/speech analysis to big-data trend analysis for digital twins – there is no singular "answer" to the best approach to Edge AI. Instead, it will be heavily use-case-dependent.
There are numerous approaches to optimizing AI models, both for server-side compute and on-device optimization. From the previous discussion, it can be seen that if localized inferencing becomes more feasible, then it will likely expand to many use-cases – especially those that can run independently on single, standalone devices. This has possible significant benefits for AI system developers – but also less-favorable implications for cloud and low-latency network providers.
Consider something intensely private, such as a bedside audio analyzer that detects sleep-apnoea, excessive snoring and other breathing disorders. The market for such a product could expand considerably if it came with a guarantee that personal data stayed on-device rather than being analyzed on the cloud. The model could be trained on the cloud, but inferencing could be performed at the Edge. If appropriate, it could communicate results with medical professionals and upload raw data if the user then permitted it later, but local processing would be a good selling point initially.
Disruptive Analysis regularly speaks to representatives of the datacentre and telecoms worlds, especially in connection with new network types such as 5G. There is very little awareness or understanding of the role of on-device compute or AI – or how rapidly it is evolving, with improvements in processor hardware or neural network optimization.
Even in more camera-centric telecoms sectors such as videoconferencing, there seems to be little awareness of a shift back from the cloud to edge (or exactly where that Edge is). There has been some recent awareness of the conflicts between end-to-end encryption and AI-driven tasks such as background blurring and live audio-captioning – but that is just one of the trade-offs that might be shifting.
The medium-term issues that seem to be underestimated are around energy budgets and privacy. If model compression and on-device Edge AI can prove not just "greener" in terms of implied CO2 footprint, but also reduce the invasiveness of mass data-collection in the cloud, then it may be embraced rapidly by many end-user groups. It may also catch the attention of policymakers and regulators, who currently have a very telecom/cloud-centric view of edge computing.
Despite this shift, it is important not to exaggerate the impact on the wider cloud and network market. This changes the calculus for some use-cases (especially real-time analysis of image, video and similar data flows) – but it does not invalidate many of the broader assumptions about future data traffic and value of high-performance networks, either wireless or wired.
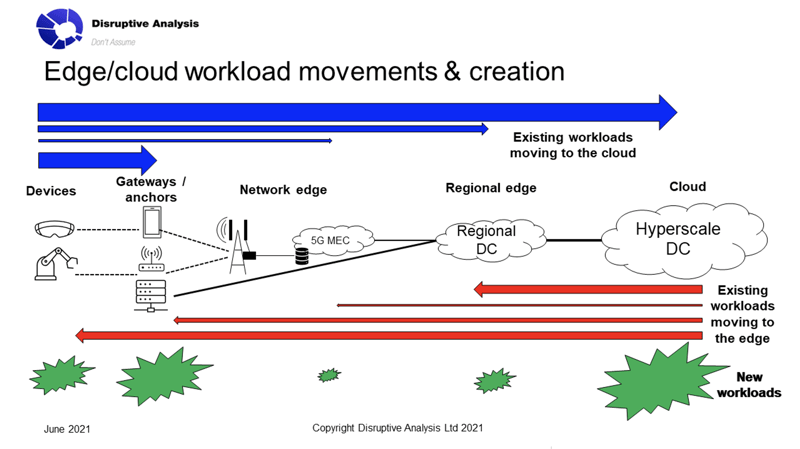
When all participants in the market understand each other's language and technology trajectories, we should hopefully see fewer poor assumptions and less unrealistic hype. There are huge advances occurring across the board – from semiconductors to DNN optimization to network performance. But each alone is not an all-purpose hammer – they are tools in a developers' toolkit.
Interested in the topic and want to learn more? Join our panel discussion combining insights from experts in Edge AI, Cloud AI, Telecommunications, Deep Learning, Semiconductor Design and more, to fuel the dialogue around AI sustainability.
