
Welcome back to the DNN model optimization series! Our recent paper on Deeplite’s unique optimization software, Neutrino™, won the “Best Deployed System” award at Innovative Applications of Artificial Intelligence 2021. For this occasion, we decided to dedicate this issue of the DNN model optimization series to a deep-dive into the champion research paper.
AI and deep learning, particularly for edge devices, have been gaining momentum and promising to empower the digitalization of many vertical markets. Despite all the excitement, deploying deep learning is easier said than done! We already looked at why you need to optimize your DNN models in one of our previous blog posts. Let’s look at ‘how’ Deeplite’s Neutrino™ framework addresses the ever-larger AI models’ optimization and paves the way for easy deployments into increasingly constrained edge devices.
Neutrino™ is an end-to-end black-box platform for fully automated DNN model compression that maintains the model accuracy. It can be seamlessly and smoothly integrated into any development and deployment pipeline, as shown in the figure below. Guided by the end-user constraints and requirements, Neutrino™ produces the optimized model that can be further used for inference, either directly deployed on the edge device or in a cloud environment.
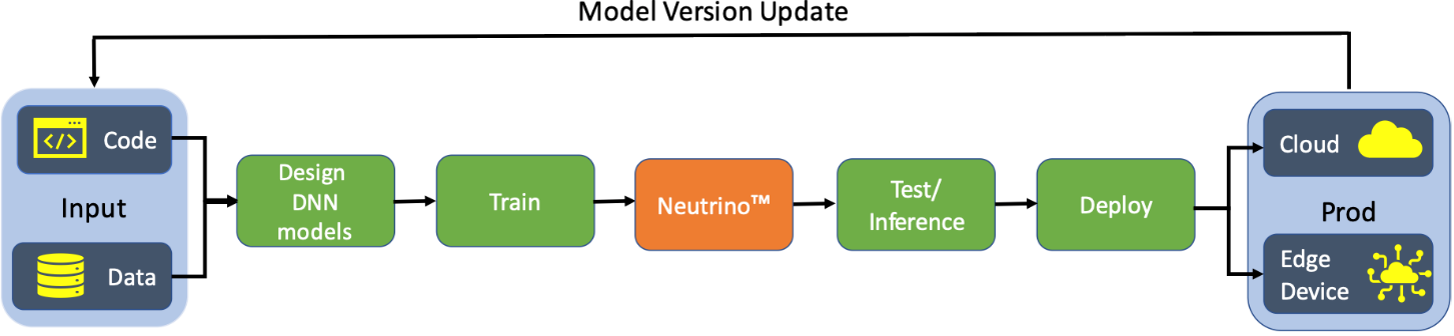
The algorithm that we used to understand, analyze, and compress the DNN model automatically for a given dataset is explained below.
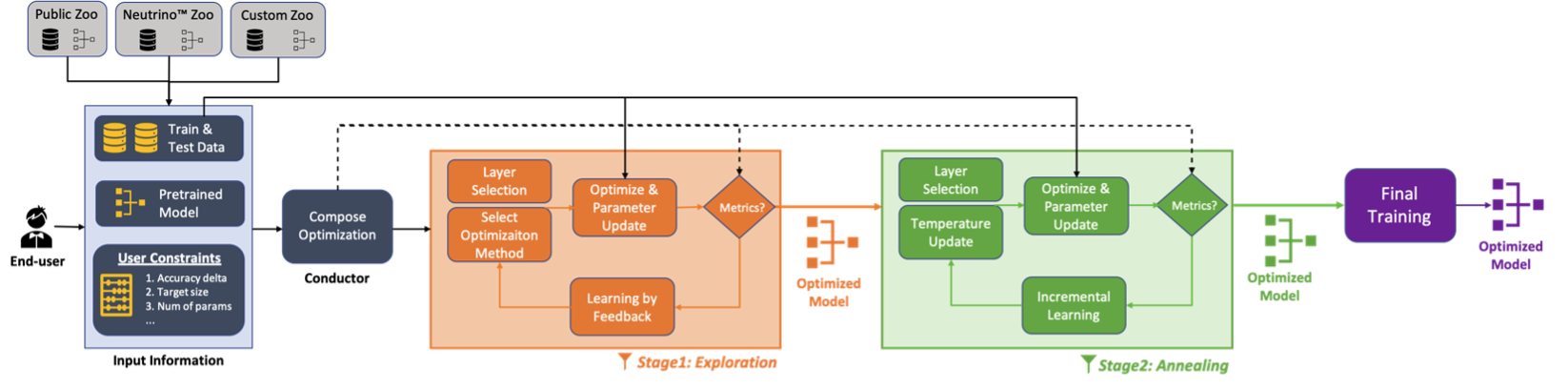
In one of our blog posts, we already answered the top 10 questions about the model compression process. To briefly explain, at Deeplite, we dynamically combine different optimization methods for different layers in a model to create a beautiful result, achieving maximum compression with minimal accuracy loss (and when we say minimal, we mean it! Look at the outcomes below).

Let’s look at an example here. Our pre-trained model has N optimizable layers: {L1, L2, ..., LN}. In a typical CNN model, the convolutional layers and the fully connected layers are optimizable, while the rest of the layers are ignored from the optimization process. The conductor analyzes the training data size, the number of output classes, model architecture, and optimization criteria, delta, and produces a composed list, CL = {c1, c2, ..., cN} of different transformation functions for different layers in the model. For any layer, Li, in the model, the composed function ci looks like this:
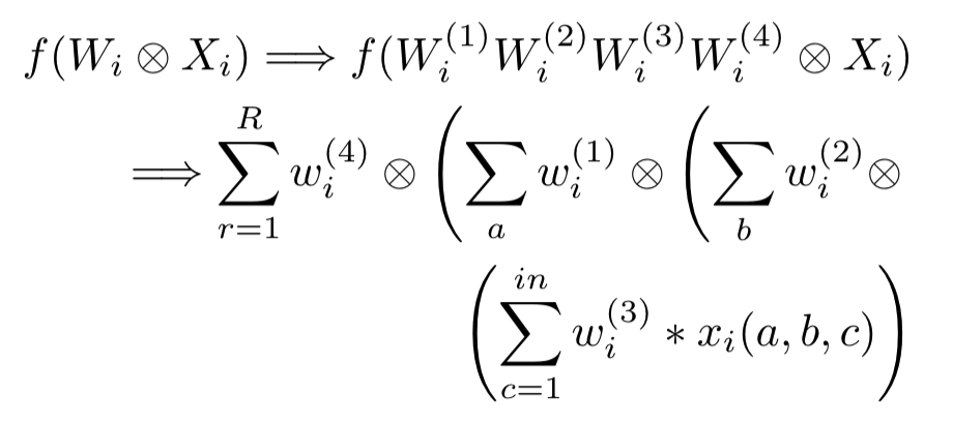
The challenge is to find an ideal size r that produces good compression retaining the model’s robustness. When r is equal to the actual size of the weight tensor of the layer, r = size(Wi), there is an over-approximation of the transformation with very low compression. However, a very small size, r → 0, produces a high compression with a lossy re-construction of the transformation.
Stage 2 optimization aims to perform aggressive compression and obtain the maximum possible compression in the required accuracy tolerance. For example, if the delta of accuracy is 1%, and stage 1 produces a 4x compression with an accuracy drop of 0.6%, stage 2 aims to advance the compression with the delta going as close as possible to 1%.
Here are the metrics we use to measure the amount of optimization and performance of Neutrino™.
Accuracy: We measure the top-1 accuracy (%) of the model. Successful optimization retains the accuracy of the original model.
Model Size: We measure the disk size (MB) occupied by the trainable parameters of the model. Smaller model size enables models to be deployed into devices with memory constraints.
MACs: We measure the model’s computational complexity by the number (billions) of Multiply-Accumulate Operation (MAC) computed across the layers of the model. The lower the number of MACs, the better optimized the model is.
Number of Parameters: We measure the total number (millions) of trainable parameters (weights and biases) in the model. Optimization aims to reduce the number of parameters.
Memory Footprint: We measure the total memory (MB) required to perform the inference on a batch of data, including the memory required by the trainable parameters and the layer activations. A lower memory footprint is achieved by better optimization.
Execution Time: We measure the time (ms) required to perform a forward pass on a batch of data. Optimized models have a lower execution time.
All the optimization experiments are run with an end-user requirement of accuracy delta of 1%. The experiments are executed with a mini-batch size of 1024, while the metrics are normalized for a mini-batch size of 1. All the experiments are run on four parallel GPU, using Horovod, and each GPU is a Tesla V100 SXM2 with 32GB memory.
|
Arch |
Model |
Accuracy (%) |
Size (MB) |
FLOPs (Billions) |
#Params (Millions) |
Memory (MB) |
Execution Time (ms) |
|
Resnet 18 |
Original |
76.8295 |
42.8014 |
0.5567 |
11.2201 |
48.4389 |
0.0594 |
|
Stage 1 |
76.7871 |
7.5261 |
0.1824 |
1.9729 |
15.3928 |
0.0494 |
|
|
Stage 2 |
75.8008 |
3.4695 |
0.0790 |
0.9095 |
10.3965 |
0.0376 |
|
|
Enhance |
-0.9300x |
12.34x |
7.05x |
12.34x |
4.66x |
1.58x |
|
|
Resnet50 |
Original |
78.0657 |
90.4284 |
1.3049 |
23.7053 |
123.5033 |
3.9926 |
|
Stage 1 |
78.7402 |
25.5877 |
0.6852 |
6.7077 |
65.2365 |
0.2444 |
|
|
Stage 2 |
77.1680 |
8.4982 |
0.2067 |
2.2278 |
43.7232 |
0.1772 |
|
|
Enhance |
-0.9400 |
10.64x |
6.31x |
10.64x |
2.82x |
1.49x |
|
|
VGG19 |
Original |
72.3794 |
76.6246 |
0.3995 |
20.0867 |
80.2270 |
1.4238 |
|
Stage 1 |
71.5918 |
3.3216 |
0.0631 |
0.8707 |
7.5440 |
0.0278 |
|
|
Stage 2 |
71.6602 |
2.6226 |
0.0479< |
0.6875 |
6.7399 |
0.0263 |
|
|
Enhance |
-0.8300 |
29.22x |
8.34x |
29.22x |
11.90x |
1.67x |
|
Arch |
Model |
Accuracy (%) |
Size (MB) |
FLOPs (Billions) |
#Params (Millions) |
Memory (MB) |
Execution Time (ms) |
|
DenseNet121 |
Original |
78.4612 |
26.8881 |
0.8982 |
7.0485 |
66.1506 |
10.7240 |
|
Stage 1 |
79.0348 |
15.7624 |
0.5477 |
4.132 |
61.8052 |
0.2814 |
|
|
Stage 2 |
77.8085 |
6.4246 |
0.1917 |
1.6842 |
48.3280 |
0.2372 |
|
|
Enhance |
-0.6500 |
4.19x |
4.69x |
4.19x |
1.37x |
1.17x |
|
|
GoogleNet |
Original |
79.3513 |
23.8743 |
1.5341 |
6.2585 |
64.5977 |
5.7186 |
|
Stage 1 |
79.4922 |
12.6389 |
0.8606 |
3.3132 |
62.1568 |
0.2856 |
|
|
Stage 2 |
78.8086 |
6.1083 |
0.3860 |
1.6013 |
51.3652 |
0.2188 |
|
|
Enhance |
-0.4900 |
3.91x |
3.97x |
3.91x |
1.26x |
1.28x |
|
|
MobileNet v1 |
Original |
66.8414 |
12.6246 |
0.0473 |
3.3095 |
16.6215 |
1.8147 |
|
Stage 1 |
66.4355 |
6.4211 |
0.0286 |
1.6833 |
10.5500 |
0.0306 |
|
|
Stage 2 |
66.6211 |
3.2878 |
0.0170 |
0.8619 |
7.3447 |
0.0286 |
|
|
Enhance |
-0.4000 |
3.84x |
2.78x |
3.84x |
2.26x |
1.13x |
|
Arch: Resnet18 Dataset |
Model |
Accuracy (%) |
Size (MB) |
FLOPs (Billions) |
#Params (Millions) |
Memory (MB) |
Execution Time (ms) |
|
Imagenet16 |
Original |
94.4970 |
42.6663 |
1.8217 |
11.1847 |
74.6332 |
0.2158 |
|
Stage 1 |
93.8179 |
3.3724 |
0.5155 |
0.8840 |
41.0819 |
0.1606 |
|
|
Stage 2 |
93.6220 |
1.8220 |
0.3206 |
0.4776 |
37.4608 |
0.1341 |
|
|
Enhance |
-0.8800 |
23.42x |
5.68x |
23.42x |
1.99x |
1.61x |
|
|
VWW (Visual Wake Words) |
Original |
93.5995 |
42.6389 |
1.8217 |
11.1775 |
74.6057 |
0.2149 |
|
Stage 1 |
93.8179 |
3.3524 |
0.4014 |
0.8788 |
39.8382 |
0.1445 |
|
|
Stage 2 |
92.6220 |
1.8309 |
0.2672 |
0.4800 |
36.6682 |
0.1296 |
|
|
Enhance |
-0.9800 |
23.29x |
6.82x |
23.29x |
2.03x |
1.66x |
Depending on the architecture of the original model, it can be observed that the model size could be compressed anywhere between ∼3x to ∼30x. VGG19 is known to be one of the highly over-parameterized CNN models. As expected, it achieved a 29.22x reduction in the number of parameters with almost ∼12x compression in the overall memory footprint and ∼an 8.3x reduction in computation complexity. The resulting VGG19 model occupies only 2.6MB as compared to the original model requiring 76.6MB.
The performance of Neutrino™ on large-scale vision datasets produces around ∼23.5x compression of ResNet18 on Imagenet16 and VWW datasets. The optimized model requires only 1.8MB as compared to the 42.6MB needed for the original model.
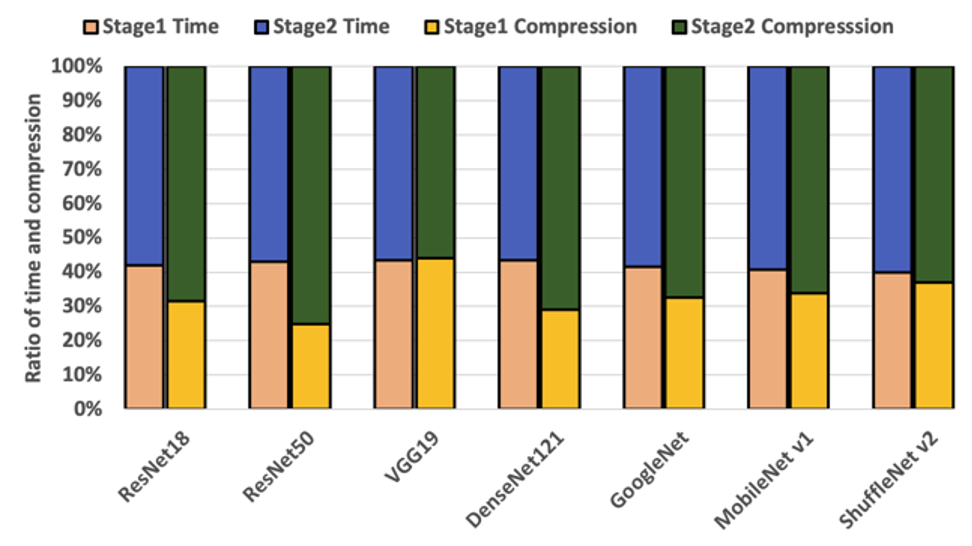
Crucially, it can be observed that Stage 2 compresses the model at least 2x more than Stage 1 compression. The overall time taken for optimization by Neutrino™, including Stage 1 and Stage 2, is shown in the figure below. It can be observed that most of the models could be optimized in less than ∼2 hours. Complex architectures with longer training times, such as Resnet50 and DenseNet121, take around ∼6 hours and ∼13 hours for optimization.
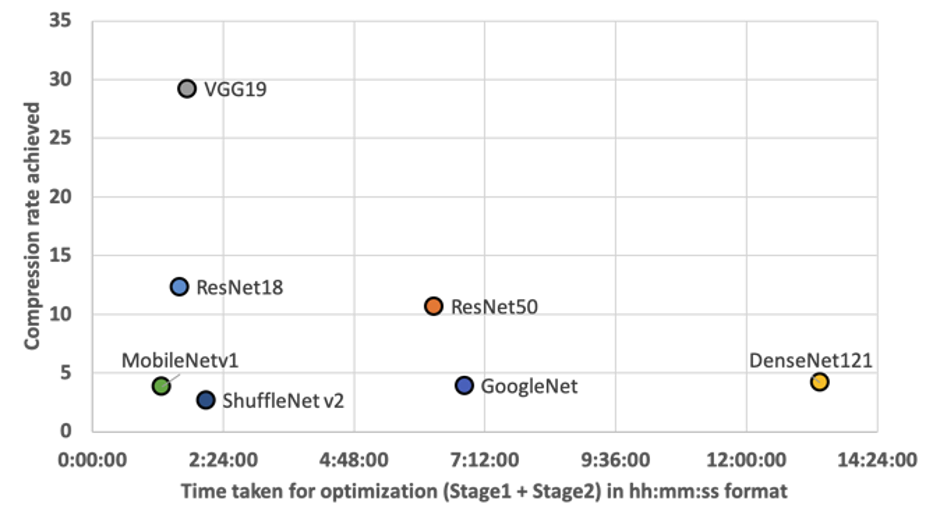
The comparison between the time taken for Stage 1 and Stage 2 compression is visually shown in the below figure. It can be observed that almost 60−70% of the overall optimization is achieved in Stage 2, while Stage 1 consumes less than ∼40% of the overall time required. This differentiation acts as a key feature of Neutrino™, where end-users who need quick optimization with less resource consumption can choose Stage 1. In contrast, those needing aggressive optimization can choose Stage 2 optimization.
Deeplite’s Neutrino™ is deployed in various production environments, and the results of the various use-cases obtained are summarized in the table below. To showcase the efficiency of Neutrino™’s performance, the optimization results are compared with other popular frameworks in the market, such as (i) Microsoft’s Neural Network Interface (NNI), Intel’s Neural Network Distiller, and (iii) Tensorflow Lite Micro. It can be observed that Neutrino™ consistently outperforms the competitors by achieving higher compression with better accuracy.
|
Use Case |
Arch |
Model |
Accuracy (%) |
Size (Bytes) |
FLOPs (Millions) |
#Params (Millions) |
|
Andes Technology Inc. |
MobileNetv1(VWW) |
Original |
88.1 |
12,836,104 |
105.7 |
3.2085 |
|
Neutrino™ |
87.6 |
188,000 |
24.6 |
0.1900 |
||
|
TensorFlow LM |
84.0 |
860,000 |
- |
0.2134 |
||
|
Prod #1 |
MobilNetV2-0.35x (Imagenet Small) |
Original |
80.9 |
1,637,076 |
66.50 |
0.4094 |
|
Neutrino™ |
80.4 |
675,200 |
50.90 |
0.1688 |
||
|
Intel Distiller |
80.4 |
1,637,076 |
66.50 |
0.2562 |
||
|
Microsoft NNI |
77.4 |
1,140,208 |
52.80 |
0.2851 |
||
|
Prod #2 |
MobileNet v2-1.0x (Imagenet Small) |
Original |
90.9 |
8,951,804 |
312.8 |
2.2367 |
|
Neutrino™ |
82.0 |
1,701,864 |
134.0 |
0.4254 |
||
|
Intel Distiller |
82.0 |
8,951,804 |
312.86 |
0.2983 |
The Neutrino™ framework is completely automated and can optimize any convolutional neural network (CNN) based architecture with no human intervention. Neutrino™ framework is distributed as Python PyPI library or Docker container, with production support for PyTorch and early developmental support for TensorFlow/Keras.
That’s it for now, folks! Remember, compression is a critical first step in making deep learning more accessible for engineers and end-users on edge devices. Unlocking highly compact, highly accurate intelligence on devices we use every day, from phones to cars and coffee makers, will have an unprecedented impact on how we use and shape new technologies.
Do you have a question or want us to look into other AI model optimization topics? Leave a comment below. We’ll be happy to follow up!
Interested in signing up for a demo of Neutrino™? Please refer to this link.

Anush Sankaran
Senior Research Scientist at Deeplite
Medium.com: @anush.sankaran
Twitter: @goodboyanush

Anastasia Hamel
Digital Marketing Manager at Deeplite
Medium.com: @anastasia.hamel
Twitter: @anastasia_hamel